
深度学习基础知识:过拟合、欠拟合、L1,L2正则化、Dropout、eargstopping、梯度消失和梯度爆炸、学习率、卷积、池化、超参数、激活函数、度量指标、Batch Size、归一化
过拟合、欠拟合
- 过拟合
定义:模型在训练集上的表现很好,但是在测试集和新数据上表现很差。
出现的原因:
- 模型复杂度过高,参数量太大
- 训练数据比较小
- 训练集和测试集分布不一致
- 样本里面的噪声数据干扰过大,导致模型过分记住了噪声特征。
解决的方法:
- 重新清洗数据,数据不纯会导致过拟合,此类情况需要重新清洗数据
- 增加训练样本数量
- 降低模型复杂度
- 数据增强
正则化:
- L1 惩罚权重绝对值, 生成简单、可解释的模型
- L2 惩罚权重平方和, 能够学习复杂数据模式
- dropout正则化
- 增大正则项系数
- 减少迭代次数
- 增大学习率
- early stopping早停
- BatchNorm
- 树结构中,可以对树进行剪枝
- 欠拟合
定义:模型在训练集和测试集上表现都很差
如何解决欠拟合:
- 添加其他特征项。组合、泛化、相关性、上下文特征、平台特征等特征是特征添加的重要手段,有时候特征项不够会导致模型欠拟合。
- 添加多项式特征。例如将线性模型添加二次项或三次项使模型泛化能力更强。例如,FM(Factorization Machine)模型、FFM(Field-aware Factorization Machine)模型,其实就是线性模型,增加了二阶多项式,保证了模型一定的拟合程度。
- 可以增加模型的复杂程度。
- 减小正则化系数。正则化的目的是用来防止过拟合的,但是现在模型出现了欠拟合,则需要减少正则化参数。
L1和L2正则化
- L1正则化直接在原来的损失函数基础上加上权重参数的绝对值:$ loss=J(w,b)+ \frac{\lambda }{2m}∑∣w∣ $
- L2正则化直接在原来的损失函数基础上加上权重参数的平方和:$ loss = J(w,b) + \frac{\lambda }{2m} ∑∥w∥_F^2 $
L1和L2正则化能够缓解过拟合的原因:
- 特征选择:L1正则化在损失函数中引入了绝对值惩罚项,这导致一些特征的权重变为零,从而使模型能够选择性地使用最重要的特征。这有助于减少模型的复杂性,提高泛化能力。相比之下,L2正则化倾向于使所有特征的权重都很小,但不会明确将某些特征的权重缩小到零,因此在特征选择方面不如L1正则化明显。
- 权重约束:L2正则化通过在损失函数中引入权重的平方和,迫使权重趋向于较小的值。这有助于防止模型过分拟合训练数据,因为较小的权重将减小模型对训练数据中噪声的敏感性。这可以有效减轻模型的过拟合问题。
- 泛化能力:通过限制模型参数的大小,L1和L2正则化有助于提高模型的泛化能力,使其更好地适应未见过的数据。这使得模型更适合于处理真实世界中的数据,而不仅仅是过度拟合训练数据。
总之,L1和L2正则化通过在损失函数中引入额外的惩罚项,有助于控制模型的复杂性并减轻过拟合问题.
Dropout
Dropout正则化
步骤:
- 遍历神经网络每一层节点,设置节点保留概率keep_prob(每一层的keep_prob可以不同,参数多的层keep_prob可以小一些,少的可以多一些)。
- 删除神经网络节点和从该节点进出的连线。
- 输入样本使用简化后的神经网络进行训练。
- 每次输入样本都要重复以上三步
Inverted Dropout(反向随机失活):
步骤:
- 产生⼀个[0,1)的随机矩阵,维度与权重矩阵相同。
- 设置节点保留概率keep_prob 并与随机矩阵比较,小于为1,大于为0。
- 将权重矩阵与0-1矩阵对应相乘得到新权重矩阵。
- 对新权重矩阵除于keep_prob(保证输⼊均值和输出均值一致),保证权重矩阵均值不变,层输出不变。
- 测试阶段不需要使用dropout,因为如果在测试阶段使用dropout会导致预测值随机变化 , 而且在训练阶段已经将权重参数除以 keep_prob 保证输出均值不变所以在刚试阶段没必要使用dropout。
Dropout起到正则化效果的原因:
- Dropout可以使部分节点失活,起到简化神经网络结构的作用,从而起到正则化的作用。
- Dropout使神经网络节点随机失活,所以神经网络节点不依赖于任何输⼊,每个输入的权重都不会很⼤。Dropout最终产⽣收缩权重的平方范数的效果,压缩权重效果类似L2正则化。
Dropout的缺点
- 增加训练时间
- 减少模型容量
eargstopping ( 早停法 )
训练时间和泛化误差的权衡。提早停⽌训练神经网络得到⼀个中等大小的W的F范数,与L2正则化类似。

在训练中计算模型在验证集上的表现,当模型在验证集上的误差开始增大时,停止训练。这样就可以避免继续训练导致的过拟合问题。
梯度消失和梯度爆炸
梯度的本意是一个向量(矢量),表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向(此梯度的方向)变化最快,变化率最大(为该梯度的模)
梯度饱和:越来越趋近一条直线(平行X轴的直线),梯度的变化很小
- 解决梯度消失的方法:
- 使用适当的激活函数:Relu及其变体
- LSTM/GRU
- 残差结构或跳跃结构
- BatchNorm
- Xavier初始化(修正w的方差,避免w过小)
- 解决梯度爆炸的方法
- 梯度裁剪:对梯度设定阈值
- 使用适当的激活函数:Relu及其变体
- 权重正则化(将w加入Loss里,如果Loss小则w也要小,而梯度爆炸是w过大[绝对值]造成的)
- Xavier初始化(修正w的方差,避免w过大)
- BatchNorm
BatchNorm
- BN的作用
- 加速SGD收敛(将batch里的数据分布变为一样),效果与特征归一化一致。
- 使分布更稳定。
- 防止过拟合。有轻微正则化效果,BN的均值和方差是在mini batch上计算得到的,含有轻微噪音。将噪音添加到隐藏单元上,这迫使后部单元不依赖于任何⼀个隐藏单元(将Batch中所有样本都被关联在了一起,网络不会从某一个训练样本中生成确定的结果),类似dropout。
- 解决梯度消失和梯度爆炸问题(使用BN后,网络的输出就不会很大,梯度就不会很小)。
- 提高激活函数准确度,增强优化器性能。
- BN的缺点
- 额外的计算开销
- 不适用于小批量大小
- 不适用于循环神经网络(RNN),因为RNN的序列长度是不一致的
- 不适用于推理阶段.BN在训练阶段与推理(预测)阶段的行为不一致。在推理阶段,无法利用批量数据的统计信息,因此需要额外的处理来适应单个样本的情况。
- 网络设计限制: 在使用BN时,需要谨慎设计网络架构,因为过多的BN层可能会导致梯度消失或梯度爆炸问题,特别是在非常深的神经网络中。
- 难以与某些正则化方法结合: BN通常与Dropout等正则化方法结合使用时效果不佳。
归一化方法
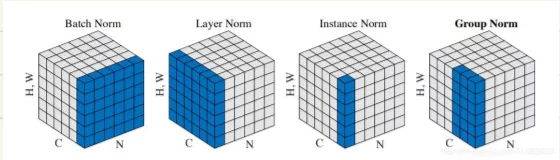
- Batch Normalization
BN是一种在每个批次的数据上进行归一化的技术。它通过计算每个特征的均值和标准差,然后对每个特征进行线性变换,以使其均值为0,标准差为1。这有助于减少梯度消失问题,并提高网络的训练速度和稳定性。 - LayerNormalization
LN与BN类似,但不是在批次上进行归一化,而是在每一层的特征上进行归一化。这使得LN更适用于循环神经网络(RNN)等不适合BN的情况。 - Instance Normalization
IN是针对于不同的batch, 不同的chennel进行归一化(计算单个C和N里的WH的均值和方差)。还是把图像的尺寸表示为[N, C, H, W]的话,IN则是针对于[H,W]进行归一化。这种方式通常会用在风格迁移的训练中。 - Group Nomalization
GN是一种介于BN和LN之间的方法,它将特征分成多个组,然后对每个组内的特征进行归一化。GN在某些情况下可以在减少计算开销的同时提供与BN类似的性能。
对比:与BN不同,LN/IN和GN都没有对batch作平均,所以当batch变化时,网络的错误率不会有明显变化。但论文的实验显示:LN和IN 在时间序列模型(RNN/LSTM)和生成模型(GAN)上有很好的效果,而GN在GAN上表现更好。
- Weight Normalization
WN是一种对网络的权重进行归一化的方法,而不是对输入数据进行归一化。它有助于减小训练中的梯度消失问题。 - Local Response Normalization
LRN是一种用于卷积神经网络(CNN)的归一化方法,它在局部窗口内对激活进行归一化。然而,它在深度网络中的使用逐渐减少,因为后来出现的方法效果更好。
卷积
深度学习中将互相关称之为卷积
作用:提取视觉特征
- 缺点:
- 输出缩小;
- 图像边缘大部分信息丢失(因为边缘区域像素点在输出中采用较少,只采用一次,解决办法用padding)
- 对噪声敏感
- 对旋转和缩放敏感
- 局部特征处理: CNN主要用于提取局部特征,对于全局或全局-局部关系的建模相对较弱。
各种核的尺寸为奇数的原因:
若是偶数,则填充为不对称填充。
若是奇数,则过滤器有⼀个中心点,便于指出过滤器的位置 。
- 卷积的优点:
- 权值共享:每个过滤器对应的输出都可以在输⼊图片的不同区域中使用相同参数卷积得到。CNN中的卷积核在整个图像上共享,这减少了参数数量,节省了计算和内存资源。这种共享权重的方式使网络更加有效。
- 局部连接: NN的卷积操作是局部连接的,即每个神经元只与输入数据的一小部分相关。这有助于捕捉图像等数据中的局部特征。
- 平移不变性: CNN通过卷积操作实现了平移不变性,即无论物体在图像中的位置如何,网络都可以识别它。这使得CNN非常适合对象识别任务。
- 多层次特征提取: CNN通常由多个卷积层组成,每一层都能够提取不同抽象级别的特征。这允许网络逐渐构建更复杂的特征表示。
- 1x1Conv(点卷积)
- 通道变换:1x1的卷积能够灵活的调控特征的深度(升维和降维)。
- 降维:减少参数量和计算量(先用少量普通卷积核再升维,或先降维再普通卷积等可以减少参数量以及计算量)。
- 特征组合:1x1卷积可以将输入特征图的不同通道进行线性组合,以生成新的特征表示。实现了跨通道的信息组合,并增加了非线性特征(实现降维和升维的操作其实就是channel间信息的线性组合变化)。
- 正则化:1x1卷积可以用于加入正则化,有助于防止过拟合。
池化
Pooling 层主要的作用是下采样,通过去掉 Feature Map 中不重要的样本,进一步减少参数数量。并且具有防止过拟合,以及保持特征的不变性(平移、旋转、尺度)的作用。缺点是不存在要学习的参数。
Pooling 的方法很多,最常用的是 Max Pooling。Max Pooling 实际上就是在 nn 的样本中取最大值,作为采样后的样本值。下图是 22 max pooling:
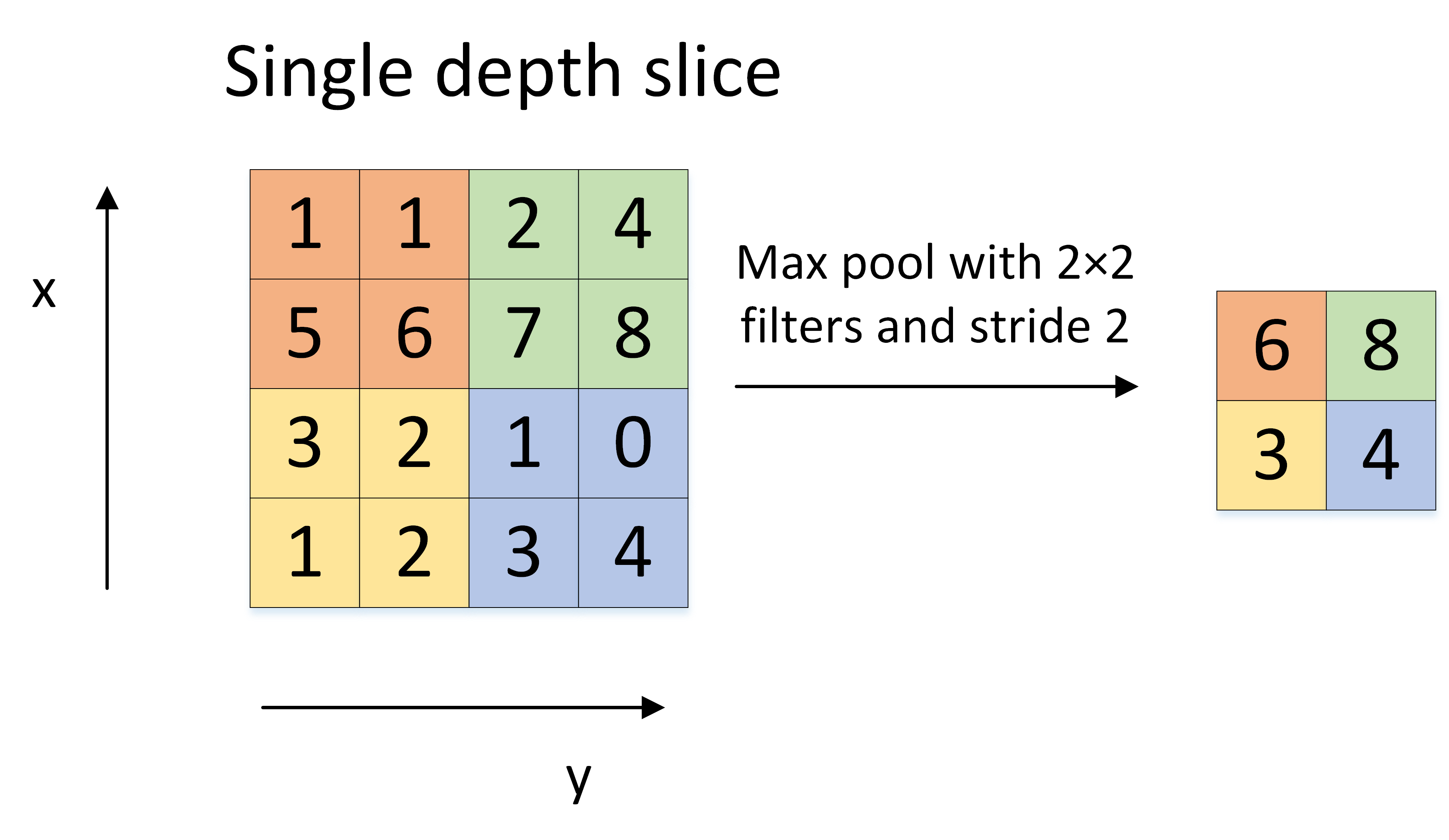
除了 Max Pooing 之外,常用的还有 Average Pooling ——取各样本的平均值。对于深度为 $ D $ 的 Feature Map,各层独立做 Pooling,因此 Pooling 后的深度仍然为 $ D $。
global average pooling求的是每一个维度的平均值。
使用Conv替换Pool的优点:Conv的参数是可学习的,可以达到保留更多数据信息和防止过滤掉有用信息的作用。
超参数
超参数 : 在机器学习的上下文中,超参数是在开始学习过程之前设置值的参数,而不是通过训练得到的参数数据。通常情况下,需要对超参数进行优化,给学习机选择一组最优超参数,以提高学习的性能和效果。
超参数通常存在于:
- 定义关于模型的更高层次的概念,如复杂性或学习能力。
- 不能直接从标准模型培训过程中的数据中学习,需要预先定义。
- 可以通过设置不同的值,训练不同的模型和选择更好的测试值来决定
超参数具体来讲比如算法中的学习率(learning rate)、梯度下降法迭代的数量(iterations)、隐藏层数目(hidden layers)、隐藏层单元数目、激活函数( activation function)都需要根据实际情况来设置,这些数字实际上控制了最后的参数和的值,所以它们被称作超参数。
如何寻找超参数的最优值?
- 猜测和检查:根据经验或直觉,选择参数,一直迭代。
- 网格搜索:让计算机尝试在一定范围内均匀分布的一组值。
- 随机搜索:让计算机随机挑选一组值。
- 贝叶斯优化:使用贝叶斯优化超参数,会遇到贝叶斯优化算法本身就需要很多的参数的困难。
- MITIE方法,好初始猜测的前提下进行局部优化。它使用BOBYQA算法,并有一个精心选择的起始点。由于BOBYQA只寻找最近的局部最优解,所以这个方法是否成功很大程度上取决于是否有一个好的起点。在MITIE的情况下,我们知道一个好的起点,但这不是一个普遍的解决方案,因为通常你不会知道好的起点在哪里。从好的方面来说,这种方法非常适合寻找局部最优解。稍后我会再讨论这一点。
- LIPO的全局优化方法。这个方法没有参数,而且经验证比随机搜索方法好。
超参数搜索一般过程
- 将数据集划分成训练集、验证集及测试集。
- 在训练集上根据模型的性能指标对模型参数进行优化。
- 在验证集上根据模型的性能指标对模型的超参数进行搜索。
- 步骤 2 和步骤 3 交替迭代,最终确定模型的参数和超参数,在测试集中验证评价模型的优劣。
其中,搜索过程需要搜索算法,一般有:网格搜索、随机搜过、启发式智能搜索、贝叶斯搜索。
激活函数
- 激活函数对模型学习、理解非常复杂和非线性的函数具有重要作用。
- 激活函数可以引入非线性因素。如果不使用激活函数,则输出信号仅是一个简单的线性函数。线性函数一个一级多项式,线性方程的复杂度有限,从数据中学习复杂函数映射的能力很小。没有激活函数,神经网络将无法学习和模拟其他复杂类型的数据,例如图像、视频、音频、语音等。
- 激活函数可以把当前特征空间通过一定的线性映射转换到另一个空间,让数据能够更好的被分类。
为什么激活函数需要非线性函数
- 假若网络中全部是线性部件,那么线性的组合还是线性,与单独一个线性分类器无异。这样就做不到用非线性来逼近任意函数。
- 使用非线性激活函数 ,以便使网络更加强大,增加它的能力,使它可以学习复杂的事物,复杂的表单数据,以及表示输入输出之间非线性的复杂的任意函数映射。使用非线性激活函数,能够从输入输出之间生成非线性映射。
预训练与微调(fine tuning)
预训练的好处
- 训练数据较少时, 难以训练复杂网络。
- 加快训练任务的收敛速度。
- 初始化效果好,有利于优化 。
什么是预训练
在CV里,网络底层参数使用其它任务学习好的参数,高层参数仍然随机初始化。之后,用该任务的训练数据训练网络,底层参数微调。
- 为什么无监督预训练可以帮助深度学习?
深度网络存在问题:
- 网络越深,需要的训练样本数越多。若用监督则需大量标注样本,不然小规模样本容易造成过拟合。深层网络特征比较多,会出现的多特征问题主要有多样本问题、规则化问题、特征选择问题。
- 多层神经网络参数优化是个高阶非凸优化问题,经常得到收敛较差的局部解;
- 梯度扩散问题,BP算法计算出的梯度随着深度向前而显著下降,导致前面网络参数贡献很小,更新速度慢。
解决方法:
逐层贪婪训练,无监督预训练(unsupervised pre-training)即训练网络的第一个隐藏层,再训练第二个…最后用这些训练好的网络参数值作为整体网络参数的初始值。
经过预训练最终能得到比较好的局部最优解。
- 什么是模型微调fine tuning
用别人的参数、修改后的网络和自己的数据进行训练,使得参数适应自己的数据,这样一个过程,通常称之为微调(fine tuning).
模型的微调举例说明:
我们知道,CNN 在图像识别这一领域取得了巨大的进步。如果想将 CNN 应用到我们自己的数据集上,这时通常就会面临一个问题:通常我们的 dataset 都不会特别大,一般不会超过 1 万张,甚至更少,每一类图片只有几十或者十几张。这时候,直接应用这些数据训练一个网络的想法就不可行了,因为深度学习成功的一个关键性因素就是大量带标签数据组成的训练集。如果只利用手头上这点数据,即使我们利用非常好的网络结构,也达不到很高的 performance。这时候,fine-tuning 的思想就可以很好解决我们的问题:我们通过对 ImageNet 上训练出来的模型(如CaffeNet,VGGNet,ResNet) 进行微调,然后应用到我们自己的数据集上。
- 微调时候网络参数是否更新?
答案:会更新。
- finetune 的过程相当于继续训练,跟直接训练的区别是初始化的时候。
- 直接训练是按照网络定义指定的方式初始化。
- finetune是用你已经有的参数文件来初始化。
- fine-tuning 模型的三种状态
- 状态一:只预测,不训练。 特点:相对快、简单,针对那些已经训练好,现在要实际对未知数据进行标注的项目,非常高效;
- 状态二:训练,但只训练最后分类层。 特点:fine-tuning的模型最终的分类以及符合要求,现在只是在他们的基础上进行类别降维。
- 状态三:完全训练,分类层+之前卷积层都训练 特点:跟状态二的差异很小,当然状态三比较耗时和需要训练GPU资源,不过非常适合fine-tuning到自己想要的模型里面,预测精度相比状态二也提高不少。
度量指标分析
详看混淆矩阵那一篇。
- FP: Fal se Positive 阴性被预测为阳性
- TP: True Positive 阳性被预测为阳性
- FN: False Negative 阳性被预测为阴性
- TN: True Negative 阴性被预测为阴性
- Accuracy
准确率,模型正确分类样本数占总样本数的比例(所有类别)
$Accuracy$ = $\frac{正确分类样本数}{所有样本数}$ = $\frac{TP+TN}{TP+TN+FP+FN}$
- F1-score
衡量模型对每个类别的预测精度和召回率是否平衡,是Precision和Recall的调和平均数。能够直观地显示模型对测试集中每个类别的泛化效果。F1值越大,学习器的性能较好。
$F1-score$ = $\frac{2}{\frac{1}{Precision}+\frac{1}{Recall}}$ = $\frac{2*Precision*Recall}{Precision+Recall}$
- precision
衡量模型对测试集中每个类别的预测准确性,能够直观地显示模型对测试集中每个类别的归纳效果。
$Precision$ = $\frac{正确分类为正例}{预测为正例的样本数}$ = $\frac{TP}{TP+FP}$
- recall
衡量模型对测试集中每个类别的相关数据的识别准确程度,能够直观地显示模型对测试集中每个类别的相关数据的识别效果。
$Recall$ = $\frac{正确分类为正例}{真实为正例样本数}$=$\frac{TP}{TP+FN}$
- Specificity
$Specificity$ = $\frac{TN}{真实为健康的样本数}$ = $\frac{TN}{FP+TN}$
- PR曲线
- 横轴是召回率(Recall),纵轴是精确率(Precision)。
- PR 曲线显示了在不同阈值下模型的精确率和召回率之间的权衡。
- 面积越大的 PR 曲线表示模型性能越好。
一个阈值对应PR曲线上的一个点。通过选择合适的阈值,比如50%,对样本进行划分,概率大于50%的就认为是正例,小于50%的就是负例,从而计算相应的精准率和召回率。(选取不同的阈值,就得到很多点,连起来就是PR曲线)
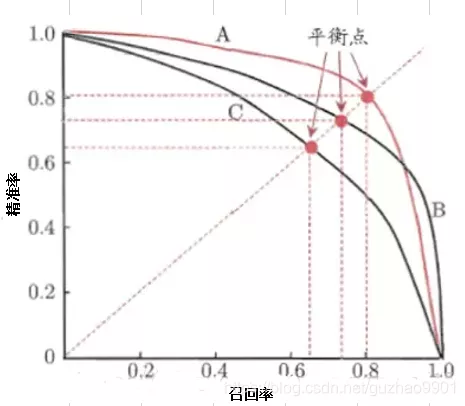
- ROC
- 横轴是假正类别率(False Positive Rate,FPR),纵轴是真正类别率(True Positive Rate,TPR,也称为召回率)。
- ROC 曲线显示了在不同阈值下模型的真正类别率和假正类别率之间的权衡。
- 曲线下面积 AUC(Area Under the Curve)用于量化 ROC 曲线的性能,AUC 越大表示模型性能越好。
模型在所有样本的(阳性/阴性)真实值和预测值计算出一个 (X=TPR, Y=1-FPR) 座标点
TPR=Recall(灵敏度)
FPR=$\frac{FP}{FP+TN}$(特异度)
ROC曲线为不同阈值下ROC坐标点组成的曲线
- AUC
AUC 是 ROC 曲线下的面积,用于度量分类模型的性能。
AUC 的值介于 0 和 1 之间,表示模型正确分类正类别样本的概率大于正确分类负类别样本的概率的概率。
AUC 为 0.5 表示模型的性能等于随机分类,AUC 大于 0.5 表示模型性能优于随机分类,AUC 等于 1 表示模型完美分类。
Batch Size
- 为什么需要 Batch_Size?
Batch的选择,首先决定的是下降的方向。
如果数据集比较小,可采用全数据集的形式,好处是:
- 由全数据集确定的方向能够更好地代表样本总体,从而更准确地朝向极值所在的方向。
- 由于不同权重的梯度值差别巨大,因此选取一个全局的学习率很困难。 Full Batch Learning 可以使用 Rprop 只基于梯度符号并且针对性单独更新各权值。
对于更大的数据集,假如采用全数据集的形式,坏处是:
- 随着数据集的海量增长和内存限制,一次性载入所有的数据进来变得越来越不可行。
- 以 Rprop 的方式迭代,会由于各个 Batch 之间的采样差异性,各次梯度修正值相互抵消,无法修正。这才有了后来 RMSProp 的妥协方案。
- Batch_Size 值的选择
假如每次只训练一个样本,即 Batch_Size = 1。线性神经元在均方误差代价函数的错误面是一个抛物面,横截面是椭圆。对于多层神经元、非线性网络,在局部依然近似是抛物面。此时,每次修正方向以各自样本的梯度方向修正,横冲直撞各自为政,难以达到收敛。
既然 Batch_Size 为全数据集或者Batch_Size = 1都有各自缺点,可不可以选择一个适中的Batch_Size值呢?
此时,可采用批梯度下降法(Mini-batches Learning)。因为如果数据集足够充分,那么用一半(甚至少得多)的数据训练算出来的梯度与用全部数据训练出来的梯度是几乎一样的。
在合理范围内,增大Batch_Size有何好处?
- 内存利用率提高了,大矩阵乘法的并行化效率提高。
- 跑完一次 epoch(全数据集)所需的迭代次数减少,对于相同数据量的处理速度进一步加快。
- 在一定范围内,一般来说 Batch_Size 越大,其确定的下降方向越准,引起训练震荡越小。
- 盲目增大 Batch_Size 有何坏处?
- 内存利用率提高了,但是内存容量可能撑不住了。
- 跑完一次 epoch(全数据集)所需的迭代次数减少,要想达到相同的精度,其所花费的时间大大增加了,从而对参数的修正也就显得更加缓慢。
- Batch_Size 增大到一定程度,其确定的下降方向已经基本不再变化。
- 调节 Batch_Size 对训练效果影响到底如何?
- Batch_Size 太小,模型表现效果极其糟糕(error飙升)。
- 随着 Batch_Size 增大,处理相同数据量的速度越快。
- 随着 Batch_Size 增大,达到相同精度所需要的 epoch 数量越来越多。
- 由于上述两种因素的矛盾, Batch_Size 增大到某个时候,达到时间上的最优。
- 由于最终收敛精度会陷入不同的局部极值,因此 Batch_Size 增大到某些时候,达到最终收敛精度上的最优。
归一化
- 归一化含义
- 归纳统一样本的统计分布性。归一化在0-1之间是统计的概率分布,归一化在 -1--1 之间是统计的坐标分布。
- 无论是为了建模还是为了计算,首先基本度量单位要同一,神经网络是以样本在事件中的统计分别几率来进行训练(概率计算)和预测,且 sigmoid 函数的取值是 0 到 1 之间的,网络最后一个节点的输出也是如此,所以经常要对样本的输出归一化处理。
- 归一化是统一在 0-1 之间的统计概率分布,当所有样本的输入信号都为正值时,与第一隐含层神经元相连的权值只能同时增加或减小,从而导致学习速度很慢。
- 另外在数据中常存在奇异样本数据,奇异样本数据存在所引起的网络训练时间增加,并可能引起网络无法收敛。为了避免出现这种情况及后面数据处理的方便,加快网络学习速度,可以对输入信号进行归一化,使得所有样本的输入信号其均值接近于 0 或与其均方差相比很小。
- 为什么要归一化?
- 为了后面数据处理的方便,归一化的确可以避免一些不必要的数值问题。
- 为了程序运行时收敛加快。
- 同一量纲。样本数据的评价标准不一样,需要对其量纲化,统一评价标准。这算是应用层面的需求。
- 避免神经元饱和。啥意思?就是当神经元的激活在接近 0 或者 1 时会饱和,在这些区域,梯度几乎为 0,这样,在反向传播过程中,局部梯度就会接近 0,这会有效地“杀死”梯度。
- 保证输出数据中数值小的不被吞食。
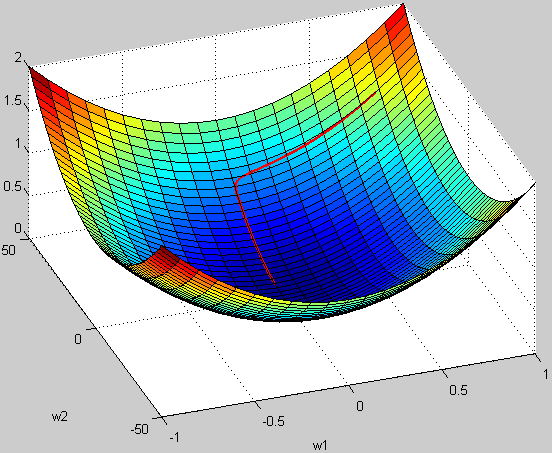
- 为什么归一化能提高求解最优解速度?
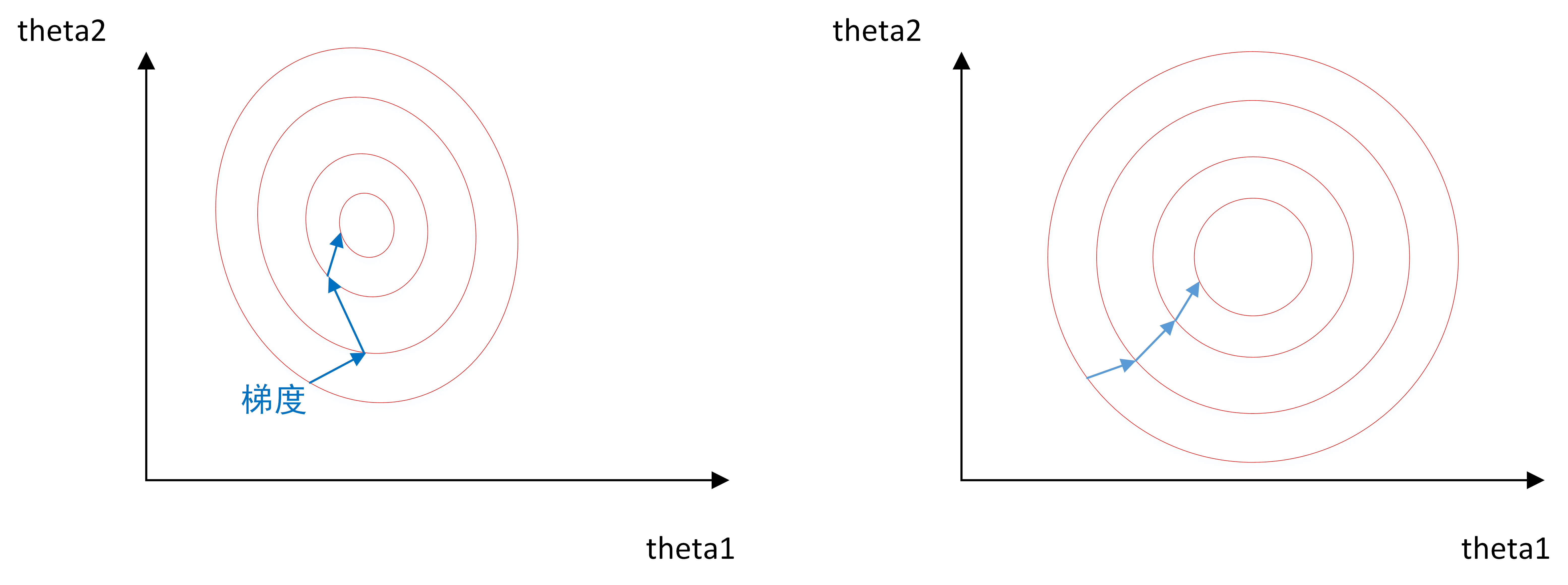
上图是代表数据是否均一化的最优解寻解过程(圆圈可以理解为等高线)。左图表示未经归一化操作的寻解过程,右图表示经过归一化后的寻解过程。
当使用梯度下降法寻求最优解时,很有可能走“之字型”路线(垂直等高线走),从而导致需要迭代很多次才能收敛;而右图对两个原始特征进行了归一化,其对应的等高线显得很圆,在梯度下降进行求解时能较快的收敛。
因此如果机器学习模型使用梯度下降法求最优解时,归一化往往非常有必要,否则很难收敛甚至不能收敛。
- 3D 图解未归一化
例子:
假设 $ w1 $ 的范围在 $ [-10, 10] $,而 $ w2 $ 的范围在 $ [-100, 100] $,梯度每次都前进 1 单位,那么在 $ w1 $ 方向上每次相当于前进了 $ 1/20 $,而在 $ w2 $ 上只相当于 $ 1/200 $!某种意义上来说,在 $ w2 $ 上前进的步长更小一些,而 $ w1 $ 在搜索过程中会比 $ w2 $ “走”得更快。
这样会导致,在搜索过程中更偏向于 $ w1 $ 的方向。走出了“L”形状,或者成为“之”字形。
- 归一化有哪些类型?
- 线性归一化
$$ x^{\prime} = \frac{x-min(x)}{max(x) - min(x)} $$
适用范围:比较适用在数值比较集中的情况。
缺点:如果 max 和 min 不稳定,很容易使得归一化结果不稳定,使得后续使用效果也不稳定。
- 标准差标准化
$$ x^{\prime} = \frac{x-\mu}{\sigma} $$
含义:经过处理的数据符合标准正态分布,即均值为 0,标准差为 1 其中 $ \mu $ 为所有样本数据的均值,$ \sigma $ 为所有样本数据的标准差。
- 非线性归一化
适用范围:经常用在数据分化比较大的场景,有些数值很大,有些很小。通过一些数学函数,将原始值进行映射。该方法包括 $ log $、指数,正切等。
- 什么是批归一化(Batch Normalization)
以前在神经网络训练中,只是对输入层数据进行归一化处理,却没有在中间层进行归一化处理。要知道,虽然我们对输入数据进行了归一化处理,但是输入数据经过 $ \sigma(WX+b) $ 这样的矩阵乘法以及非线性运算之后,其数据分布很可能被改变,而随着深度网络的多层运算之后,数据分布的变化将越来越大。如果我们能在网络的中间也进行归一化处理,是否对网络的训练起到改进作用呢?答案是肯定的。
这种在神经网络中间层也进行归一化处理,使训练效果更好的方法,就是批归一化Batch Normalization(BN)。
下面我们来说一下BN算法的优点:
- 减少了人为选择参数。在某些情况下可以取消 dropout 和 L2 正则项参数,或者采取更小的 L2 正则项约束参数;
- 减少了对学习率的要求。现在我们可以使用初始很大的学习率或者选择了较小的学习率,算法也能够快速训练收敛;
- 可以不再使用局部响应归一化。BN 本身就是归一化网络(局部响应归一化在 AlexNet 网络中存在)
- 破坏原来的数据分布,一定程度上缓解过拟合(防止每批训练中某一个样本经常被挑选到,文献说这个可以提高 1% 的精度)。
- 减少梯度消失,加快收敛速度,提高训练精度。
- 批归一化和群组归一化比较
| 名称 | 特点 |
|---|---|
| 批量归一化(Batch Normalization,以下简称 BN) | 可让各种网络并行训练。但是,批量维度进行归一化会带来一些问题——批量统计估算不准确导致批量变小时,BN 的误差会迅速增加。在训练大型网络和将特征转移到计算机视觉任务中(包括检测、分割和视频),内存消耗限制了只能使用小批量的 BN。 |
| 群组归一化 Group Normalization (简称 GN) | GN 将通道分成组,并在每组内计算归一化的均值和方差。GN 的计算与批量大小无关,并且其准确度在各种批量大小下都很稳定。 |
| 比较 | 在 ImageNet 上训练的 ResNet-50上,GN 使用批量大小为 2 时的错误率比 BN 的错误率低 10.6% ;当使用典型的批量时,GN 与 BN 相当,并且优于其他标归一化变体。而且,GN 可以自然地从预训练迁移到微调。在进行 COCO 中的目标检测和分割以及 Kinetics 中的视频分类比赛中,GN 可以胜过其竞争对手,表明 GN 可以在各种任务中有效地取代强大的 BN。 |
- Batch Normalization在什么时候用比较合适?
- 在CNN中,BN应作用在非线性映射前。在神经网络训练时遇到收敛速度很慢,或梯度爆炸等无法训练的状况时可以尝试BN来解决。另外,在一般使用情况下也可以加入BN来加快训练速度,提高模型精度。
- BN比较适用的场景是:每个mini-batch比较大,数据分布比较接近。在进行训练之前,要做好充分的shuffle,否则效果会差很多。另外,由于BN需要在运行过程中统计每个mini-batch的一阶统计量和二阶统计量,因此不适用于动态的网络结构和RNN网络。
学习率
- 学习率的作用
- 在机器学习中,监督式学习通过定义一个模型,并根据训练集上的数据估计最优参数。梯度下降法是一个广泛被用来最小化模型误差的参数优化算法。梯度下降法通过多次迭代,并在每一步中最小化成本函数(cost 来估计模型的参数。学习率 (learning rate),在迭代过程中会控制模型的学习进度。
- 在梯度下降法中,都是给定的统一的学习率,整个优化过程中都以确定的步长进行更新, 在迭代优化的前期中,学习率较大,则前进的步长就会较长,这时便能以较快的速度进行梯度下降,而在迭代优化的后期,逐步减小学习率的值,减小步长,这样将有助于算法的收敛,更容易接近最优解。故而如何对学习率的更新成为了研究者的关注点。
- 在模型优化中,常用到的几种学习率衰减方法有:分段常数衰减、多项式衰减、指数衰减、自然指数衰减、余弦衰减、线性余弦衰减、噪声线性余弦衰减
Dropout 系列问题
- 为什么要正则化?
- 深度学习可能存在过拟合问题——高方差,有两个解决方法,一个是正则化,另一个是准备更多的数据,这是非常可靠的方法,但你可能无法时时刻刻准备足够多的训练数据或者获取更多数据的成本很高,但正则化通常有助于避免过拟合或减少你的网络误差。
- 如果你怀疑神经网络过度拟合了数据,即存在高方差问题,那么最先想到的方法可能是正则化,另一个解决高方差的方法就是准备更多数据,这也是非常可靠的办法,但你可能无法时时准备足够多的训练数据,或者,获取更多数据的成本很高,但正则化有助于避免过度拟合,或者减少网络误差。
- 理解dropout正则化
- Dropout可以随机删除网络中的神经单元,它为什么可以通过正则化发挥如此大的作用呢?
- 直观上理解:不要依赖于任何一个特征,因为该单元的输入可能随时被清除,因此该单元通过这种方式传播下去,并为单元的四个输入增加一点权重,通过传播所有权重,dropout将产生收缩权重的平方范数的效果,和之前讲的L2正则化类似;实施dropout的结果实它会压缩权重,并完成一些预防过拟合的外层正则化;L2对不同权重的衰减是不同的,它取决于激活函数倍增的大小。
- dropout率的选择
- 经过交叉验证,隐含节点 dropout 率等于 0.5 的时候效果最好,原因是 0.5 的时候 dropout 随机生成的网络结构最多。
- dropout 也可以被用作一种添加噪声的方法,直接对 input 进行操作。输入层设为更接近 1 的数。使得输入变化不会太大(0.8)
- 对参数 $ w $ 的训练进行球形限制 (max-normalization),对 dropout 的训练非常有用。
- 球形半径 $ c $ 是一个需要调整的参数,可以使用验证集进行参数调优。
- dropout 自己虽然也很牛,但是 dropout、max-normalization、large decaying learning rates and high momentum 组合起来效果更好,比如 max-norm regularization 就可以防止大的learning rate 导致的参数 blow up。
- 使用 pretraining 方法也可以帮助 dropout 训练参数,在使用 dropout 时,要将所有参数都乘以 $ 1/p $
- dropout有什么缺点?
dropout一大缺点就是代价函数J不再被明确定义,每次迭代,都会随机移除一些节点,如果再三检查梯度下降的性能,实际上是很难进行复查的。定义明确的代价函数J每次迭代后都会下降,因为我们所优化的代价函数J实际上并没有明确定义,或者说在某种程度上很难计算,所以我们失去了调试工具来绘制这样的图片。我通常会关闭dropout函数,将keep-prob的值设为1,运行代码,确保J函数单调递减。然后打开dropout函数,希望在dropout过程中,代码并未引入bug。我觉得你也可以尝试其它方法,虽然我们并没有关于这些方法性能的数据统计,但你可以把它们与dropout方法一起使用。