
Python常用的语法和函数.
.upper():转换为大写;lower():转换为小写
.upper()方法:
该方法将字符串中的所有字符转换为大写字母,并返回一个新的字符串,原始字符串不受影响。
>>> strs = 'abcd12efg'
>>> strs.upper() # 所有字母全大写
'ABCD12EFG'
>>> strs.upper().title() # 单词首字母大写
'Abcd12Efg'
>>> strs.title() # 字符串中的单词的首字母转换为大写,而其他字母转换为小写
'Abcd12Efg'
>>> strs.capitalize() # 字符串首字母大写
'Abcd12efg'
>>> "12abc".capitalize()
'12abc'.lower()方法
该方法将字符串中的所有字符转换为小写字母,并返回一个新的字符串,原始字符串不受影响。
text = "Hello, World!"
lower_text = text.lower()
print(lower_text) # 输出: "hello, world!".title():字符串中的单词的首字母转换为大写,而其他字母转换为小写
.title() 方法是 Python 字符串的一个方法,用于将字符串中的单词的首字母转换为大写,而其他字母转换为小写,从而使字符串看起来像一个标题或者句子的开头。具体来说,它将字符串中每个单词的第一个字母大写化,其余字母小写化。
str.title()text = "hello world"
title_text = text.title()
print(title_text) # 输出: "Hello World"strip()删除空格
strip()只会移除字符串两端的字符,而不会移除字符串中间的字符。如果要移除中间的字符,可以考虑使用其他字符串方法,比如 replace() 或正则表达式。
string.strip([characters])参数:
- characters(可选):要从字符串两端移除的字符集合。如果不提供这个参数,默认移除空白字符。
- strip() 方法返回一个新的字符串,其中移除了指定字符集合或空白字符。原始字符串本身不会被修改,而是生成一个新的字符串。
strip():删除首尾空格;rstrip():仅删除右空格;lstrip():仅删除右空格;
strs = ' I like python '
one = strs.strip()
print(one) # 'I like python'
two = strs.rstrip()
print(two) # ' I like python'
text = " Hello, World! "
stripped_text = text.strip() # 默认移除空白字符
print(stripped_text) # 输出: "Hello, World!"
text = "---Hello, World!---"
stripped_text = text.strip('-') # 移除指定字符 "-"
print(stripped_text) # 输出: "Hello, World!"
text = " Hello, World! "
stripped_text = text.strip(' H!') # 移除空格、大写字母 H 和感叹2023-09-03 12:17:41 星期日号 !
print(stripped_text) # 输出: "ello, World"匹配子串:count()、index()、find()、in
count()函数没有匹配到对象返回0,如果匹配到,则返回指定元素在列表中出现的次数。index()函数没有匹配到对象报错value Error,如果匹配到,则返回指定元素在列表中第一次出现的索引位置。find()函数没有匹配到对象返回-1,如果匹配到,则返回子字符串在原始字符串中第一次出现的索引位置。in没有匹配到对象返回false,如果匹配到,则返回True。
count
list.count(element)其中:
- element 是要统计出现次数的元素。
- count() 方法返回指定元素在列表中出现的次数。
fruits = ["apple", "banana", "cherry", "apple", "date", "apple"]
# 统计 "apple" 出现的次数
apple_count = fruits.count("apple")
print(apple_count) # 输出: 3
# 统计 "cherry" 出现的次数
cherry_count = fruits.count("cherry")
print(cherry_count) # 输出: 1
# 统计 "grape" 出现的次数(不存在于列表中,所以次数为 0)
grape_count = fruits.count("grape")
print(grape_count) # 输出: 0index()
list.index(element, start, end)其中:
- element 是要查找的元素。
- start 是可选参数,指定开始搜索的索引位置(包含在搜索范围内)。
- end 是可选参数,指定结束搜索的索引位置(不包含在搜索范围内)。
fruits = ["apple", "banana", "cherry", "apple", "date", "apple"]
# 查找 "banana" 的索引位置
banana_index = fruits.index("banana")
print(banana_index) # 输出: 1
# 从索引位置 2 开始查找 "apple" 的索引位置
apple_index = fruits.index("apple", 2)
print(apple_index) # 输出: 3
# 在索引位置 1 到 5 之间查找 "date" 的索引位置
date_index = fruits.index("date", 1, 5) # 注意:不包括结束索引 5
print(date_index) # 输出: 4
# 查找不存在的元素 "grape",会引发 ValueError 异常
try:
grape_index = fruits.index("grape")
except ValueError as e:
print("ValueError:", e)find()
string.find(substring, start, end)其中:
- substring 是要查找的子字符串。
- start 是可选参数,指定开始搜索的索引位置(包含在搜索范围内)。
- end 是可选参数,指定结束搜索的索引位置(不包含在搜索范围内)。
text = "Hello, World! This is an example."
# 查找 "World" 的索引位置
world_index = text.find("World")
print(world_index) # 输出: 7
# 从索引位置 13 开始查找 "is" 的索引位置
is_index = text.find("is", 13)
print(is_index) # 输出: 16
# 在索引位置 7 到 20 之间查找 "example" 的索引位置
example_index = text.find("example", 7, 20) # 注意:不包括结束索引 20
print(example_index) # 输出: -1,因为 "example" 不在指定范围内
# 查找不存在的子字符串 "apple",会返回 -1
apple_index = text.find("apple")
print(apple_index) # 输出: -1.rfind()
rfind() 是 Python 字符串(String)对象的一个方法,用于查找子字符串在原字符串中最后一次出现的位置(索引)。如果子字符串未找到,则返回 -1。rfind() 方法的语法如下:
str.rfind(sub[, start[, end]])其中:
- sub 是要查找的子字符串。
- start 是可选参数,用于指定开始查找的位置,默认为 0。
- end 是可选参数,用于指定结束查找的位置,默认为字符串的末尾。
text = "Hello, world! Hello, Python!"
# 查找子字符串 "Hello"
position = text.rfind("Hello")
print(position) # 输出: 14
# 从索引位置 15 开始查找
position = text.rfind("Hello", 15)
print(position) # 输出: -1
# 在指定范围内查找
position = text.rfind("Hello", 0, 12)
print(position) # 输出: 0
# 查找子字符串 "Python"
position = text.rfind("Python")
print(position) # 输出: 21in
value in sequence其中:
- value 是要查找的值。
- sequence 是要查找的序列,如字符串、列表、元组等。
# 判断字符串中是否包含特定子字符串
text = "Hello, World!"
contains_hello = "Hello" in text
contains_apple = "apple" in text
print(contains_hello) # 输出: True
print(contains_apple) # 输出: False
# 判断列表中是否包含特定元素
fruits = ["apple", "banana", "cherry"]
contains_banana = "banana" in fruits
contains_grape = "grape" in fruits
print(contains_banana) # 输出: True
print(contains_grape) # 输出: False参数传递
def chanageList(nums):
nums.append('c')
print("nums", nums) # nums ['a', 'b', 'c']
str1 = ['a', 'b']
# 调用函数
chanageList(str1)
print("str1", str1) # str1 ['a', 'b', 'c']Python参数传递采用的是“传对象引用”的方式。实际上,这种方式相当于传值和传引用的一种综合。
- 如果函数收到的是一个可变对象(比如字典 或者列表)的引用,就能修改对象的原始值——相当于通过“传引用”来传递对象。
- 如果函数收到的是一个不可变对象(比如数字、字符串或者元组)的引用,就不能 直接修改原始对象——相当于通过“传值”来传递对象。
Example1:
def chanageList(nums):
nums += 1
print("nums", nums) # nums 124
str1 = 123
# 调用函数
chanageList(str1)
print("str1", str1) # str1 123
==========================================
def chanageList(nums):
nums += "AS"
print("nums", nums) # nums strAS
str1 = "str"
# 调用函数
chanageList(str1)
print("str1", str1) # str1 strExample2:
a = [1]
b = 2
c = 1
def fn(lis,obj):
lis.append(b)
obj = obj + 1
return lis,obj
fn(a,c)
print(fn(a,c)) # ([1, 2, 2], 2).pop()移除并返回指定索引位置
list.pop([index])参数:
- index(可选):要移除的元素的索引位置。如果不提供索引,默认移除并返回列表中的最后一个元素。
- .pop() 方法会返回被移除的元素,并且在列表中删除它。如果不提供索引,它会默认操作列表的最后一个元素。
fruits = ["apple", "banana", "cherry", "date"]
# 移除并返回最后一个元素
last_fruit = fruits.pop()
print(last_fruit) # 输出: "date"
print(fruits) # 输出: ["apple", "banana", "cherry"]
# 移除并返回指定索引位置的元素(这里索引为 1)
second_fruit = fruits.pop(1)
print(second_fruit) # 输出: "banana"
print(fruits) # 输出: ["apple", "cherry"]* 运算也表示元组复制组合
truple = (1, 2, 3)
print(truple*2) # (1, 2, 3, 1, 2, 3)
print(truple) # (1, 2, 3)元组不可变,*计算得到的是新的元组
open方法打开文件
open(file, mode, buffering, encoding, errors, newline, closefd, opener)参数:
- file:要打开的文件名(包括路径)。
- mode:打开文件的模式,可以是 "r"(只读)、"w"(写入,会覆盖已存在的文件)、"a"(追加,将数据写入文件末尾)、"x"(创建新文件并写入)、"b"(二进制模式)、"t"(文本模式)等组合。
- buffering:用于控制缓冲行为的可选参数,通常可以忽略。
- encoding:指定文件编码的可选参数,通常在文本模式下使用,例如 "utf-8"。
- errors:指定编码错误处理的可选参数,通常可以忽略。
- newline:指定换行符的可选参数,通常在文本模式下使用。
- closefd:在传递一个文件描述符时,用于控制文件是否关闭的可选参数。
- opener:一个自定义的打开器函数,通常可以忽略。
# 以只读模式打开文件
file = open("example.txt", "r")
# 以写入模式打开文件(会覆盖已存在的内容)
file = open("example.txt", "w")
# 以追加模式打开文件(将数据写入文件末尾)
file = open("example.txt", "a")
# 以文本模式打开文件,并指定编码
file = open("example.txt", "r", encoding="utf-8")
# 以二进制模式打开文件
file = open("example.bin", "rb")
# 以二进制模式打开文件以进行追加操作
file = open("example.bin", "ab").sort()排序
sort()方法是 Python 中列表(List)的一个方法,用于对列表进行原地排序,即改变列表自身的顺序。这个方法会按升序(从小到大)对列表元素进行排序,或者按指定的排序规则进行排序。默认升序。
list.sort(key=None, reverse=False)参数:
- key(可选):一个函数,用于指定排序的规则。默认情况下,元素将按其自身的值进行排序。
- reverse(可选):一个布尔值,用于指定是否按降序(从大到小)进行排序。默认为 False,即按升序排序。
numbers = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
# 默认按升序排序
numbers.sort()
print(numbers) # 输出: [1, 1, 2, 3, 3, 4, 5, 5, 5, 6, 9]
# 按降序排序
numbers.sort(reverse=True)
print(numbers) # 输出: [9, 6, 5, 5, 5, 4, 3, 3, 2, 1, 1]
# 自定义排序规则,按元素的长度排序
words = ["apple", "banana", "cherry", "date", "elderberry"]
words.sort(key=len)
print(words) # 输出: ['date', 'apple', 'cherry', 'banana', 'elderberry']需要注意的是,sort() 方法会改变原始列表,并且不会返回一个新的排序后的列表。如果你想保留原始列表并创建一个新的排序后的列表,可以使用 sorted() 函数,它会生成新的序列,生成的新序列和原序列id值必然不同如下所示:
numbers = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
# 使用 sorted() 函数进行排序,原始列表保持不变
sorted_numbers = sorted(numbers)
print(sorted_numbers) # 输出: [1, 1, 2, 3, 3, 4, 5, 5, 5, 6, 9]
print(numbers) # 输出: [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]这样,sorted() 函数会返回一个新列表,而不会修改原始列表。
.append()和.insert()增加或插入元素
.append()
向列表的末尾添加一个元素。这个方法的语法如下:
list.append(element)其中:
- element 是要添加到列表末尾的元素。
- append() 方法会修改原始列表,将指定的元素添加到列表的末尾。以下是一些示例:
fruits = ["apple", "banana", "cherry"]
# 向列表末尾添加一个新元素
fruits.append("date")
print(fruits) # 输出: ['apple', 'banana', 'cherry', 'date']
# 可以连续多次使用 append() 来添加多个元素
fruits.append("elderberry")
fruits.append("fig")
print(fruits) # 输出: ['apple', 'banana', 'cherry', 'date', 'elderberry', 'fig'].insert()
用于在指定索引位置== 前 ==插入一个元素。这个方法的语法如下:
list.insert(index, element)其中:
- index 是要插入元素的索引位置。新元素插入到索引位置前。
- element 是要插入到列表中的元素。
- insert() 方法会修改原始列表,在指定的索引位置插入指定的元素,原来的元素向后移动。以下是一些示例:
fruits = ["apple", "banana", "cherry"]
# 在索引位置 1 插入一个新元素 "date"
fruits.insert(1, "date")
print(fruits) # 输出: ['apple', 'date', 'banana', 'cherry']
# 在索引位置 0 插入一个新元素 "elderberry"
fruits.insert(0, "elderberry")
print(fruits) # 输出: ['elderberry', 'apple', 'date', 'banana', 'cherry']
fruits.insert(-2, "watermelon")
print(fruits) # 输出: ['elderberry', 'apple', 'date', 'watermelon', 'banana', 'cherry']需要注意的是,如果指定的索引位置超出了列表的范围(比如大于列表长度),insert() 方法会将元素添加到列表的末尾。如果要确保索引位置有效,可以使用 len() 函数获取列表的长度来进行检查。
enumerate()
enumerate()是 Python 内置函数,用于同时迭代列表(或其他可迭代对象)的索引和元素。它返回一个枚举对象,包含了索引和对应的元素,可以用于在循环中获取索引和元素的值。enumerate() 的语法如下:
enumerate(iterable, start=0)其中:
- iterable 是要迭代的可迭代对象,通常是列表、元组、字符串等。
- start 是可选参数,用于指定索引的起始值,默认为 0。
- enumerate() 返回一个可迭代的枚举对象,每个元素都是一个包含索引和元素值的元组。
fruits = ["apple", "banana", "cherry"]
# 使用 enumerate 迭代列表并获取索引和元素
for index, fruit in enumerate(fruits):
print(f"Index {index}: {fruit}")
# 输出:
# Index 0: apple
# Index 1: banana
# Index 2: cherrylambda
lambda 表达式,也称为匿名函数,是一种简单的函数定义方式,通常用于创建小型、一次性的函数。lambda 表达式的语法如下:
lambda arguments: expression其中:
- arguments 是函数的参数列表,可以包含零个或多个参数,多个参数之间用逗号分隔。
- expression 是一个表达式,用于定义函数的计算逻辑,并且在函数被调用时返回结果。
lambda 函数通常在需要一个简单函数作为参数传递给其他函数时非常有用,例如在 map()、filter()、sorted() 等函数中。以下是一些示例:
# 使用 lambda 函数定义一个函数,计算两个数的和
add = lambda x, y: x + y
result = add(3, 5)
print(result) # 输出: 8
# 使用 lambda 函数在列表中对每个元素进行平方操作
numbers = [1, 2, 3, 4, 5]
squared_numbers = list(map(lambda x: x**2, numbers))
print(squared_numbers) # 输出: [1, 4, 9, 16, 25]
# 使用 lambda 函数筛选出列表中的奇数
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9]
odd_numbers = list(filter(lambda x: x % 2 != 0, numbers))
print(odd_numbers) # 输出: [1, 3, 5, 7, 9]
# 使用 lambda 函数在列表中对元素进行排序
fruits = ["apple", "banana", "cherry", "date", "elderberry"]
sorted_fruits = sorted(fruits, key=lambda x: len(x))
print(sorted_fruits) # 输出: ['date', 'apple', 'cherry', 'banana', 'elderberry']filter:筛选可迭代对象(如列表、元组等)中的元素
filter(function, iterable)其中:
- function 是一个函数,用于定义筛选条件。这个函数接受一个元素作为参数,返回 True 表示保留该元素,返回 False 表示排除该元素。
- iterable 是要筛选的可迭代对象,如列表、元组等。
- filter() 函数返回一个可迭代对象,其中包含了满足条件的元素。需要注意的是,返回的结果是一个迭代器(iterator),因此需要将其转换为列表或其他可迭代对象来访问结果。
# 定义一个筛选函数,用于保留奇数
def is_odd(number):
return number % 2 != 0
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9]
# 使用 filter() 筛选出奇数
odd_numbers = filter(is_odd, numbers)
# 将结果转换为列表
odd_numbers_list = list(odd_numbers)
print(odd_numbers_list) # 输出: [1, 3, 5, 7, 9]另一种常见的方式是使用 lambda 函数来定义筛选条件,如下所示:
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9]
# 使用 lambda 函数筛选出奇数
odd_numbers = filter(lambda x: x % 2 != 0, numbers)
# 将结果转换为列表
odd_numbers_list = list(odd_numbers)
print(odd_numbers_list) # 输出: [1, 3, 5, 7, 9]map():对每个元素应用一个指定的函数
map()函数是 Python 内置函数,用于对可迭代对象(如列表、元组等)的每个元素应用一个指定的函数,然后返回一个包含结果的可迭代对象。map() 函数的语法如下:
map(function, iterable, ...)其中:
- function 是一个函数,用于对可迭代对象中的每个元素进行操作。可以是内置函数、自定义函数或者 lambda 函数。
- iterable 是要处理的可迭代对象,可以是列表、元组、字符串等。
map() 函数返回一个迭代器,它包含了将函数应用到可迭代对象中每个元素后的结果。通常,你需要将结果转换为列表或其他数据结构以访问这些结果。
Example:
# 定义一个函数,用于将字符串转换为大写
def make_uppercase(s):
return s.upper()
# 定义一个列表
words = ["apple", "banana", "cherry", "date"]
# 使用 map() 函数将函数应用到列表中的每个元素
uppercase_words = map(make_uppercase, words)
# 将结果转换为列表
result = list(uppercase_words)
print(result) # ['APPLE', 'BANANA', 'CHERRY', 'DATE']set():无序、不重复的元素集合,它类似于列表或元组,但不允许包含重复的元素。
set()是 Python 内置函数,用于创建一个集合(Set)数据结构。集合是一个无序、不重复的元素集合,它类似于列表或元组,但不允许包含重复的元素。set() 函数的语法如下:
set(iterable)其中:
- iterable 是一个可迭代对象,可以是列表、元组、字符串等。
set() 函数将可迭代对象中的元素添加到集合中,并去除其中的重复元素,从而创建一个包含不重复元素的集合。
Example:
# 使用 set() 函数创建一个集合
fruits_set = set(["apple", "banana", "cherry", "apple", "date"])
print(fruits_set) # 输出: {'banana', 'apple', 'cherry', 'date'}
# 使用 set() 函数创建一个集合,可以使用字符串
colors_set = set("red green blue red blue")
print(colors_set) # 输出: {'r', 'b', 'd', ' ', 'l', 'e', 'g', 'u', 'n'}
# 使用 set() 函数创建一个空集合
empty_set = set()
print(empty_set) # 输出: set()fromkeys():创建一个新的字典
fromkeys()方法是 Python 字典(Dictionary)对象的一个方法,用于创建一个新的字典,其中包含指定的键和相同的默认值(默认为 None)。这个方法的语法如下:
dict.fromkeys(iterable, value)其中:
- iterable 是一个可迭代对象,包含了要作为字典的键的元素。
- value 是可选参数,用于指定要分配给每个键的默认值。如果不提供该参数,默认值为 None。
fromkeys()方法会返回一个新的字典,其中包含了指定的键和默认值。以下是一些示例:# 使用 fromkeys() 创建一个字典,指定键和默认值
keys = ["a", "b", "c"]
default_value = 0
new_dict = dict.fromkeys(keys, default_value)
print(new_dict) # 输出: {'a': 0, 'b': 0, 'c': 0}
# 使用 fromkeys() 创建一个字典,不提供默认值,默认为 None
keys = ["x", "y", "z"]
new_dict = dict.fromkeys(keys)
print(new_dict) # 输出: {'x': None, 'y': None, 'z': None}需要注意的是,fromkeys() 方法不会修改原始字典,而是创建一个新的字典。这个方法通常用于初始化一个字典,以便后续将不同的值与键关联。如果需要将不同的默认值与不同的键关联,可以使用循环或字典推导式来创建字典。
python中的复数:complex()或者直接创建
在 Python 中,复数(Complex Numbers)是由实部和虚部组成的数值类型。实部和虚部都是浮点数。复数用于表示那些包含虚数单位 j(或 J)的数值,其中虚数单位 j 表示负一的平方根,即 j^2 = -1。复数的一般形式如下:
a + bj其中:
- a 是实部(real part),表示实数部分。
- b 是虚部(imaginary part),表示虚数部分。
- j(或 J)是虚数单位。可以大写也可以小写。
Python 中的复数可以使用complex()构造函数来创建,也可以直接在数学表达式中使用虚数单位 j 来定义。例如:
# 使用 complex() 构造函数创建复数
z1 = complex(1, 2) # 1 + 2j
# 直接定义复数
z2 = 3 + 4j # 3 + 4j
# 输出复数
print(z1) # 输出: (1+2j)
print(z2) # 输出: (3+4j)Python 支持各种复数操作,例如加法、减法、乘法、除法、取模等。你可以使用复数的实部和虚部属性来访问它们的值,例如z.real和z.imag。
z1 = 1 + 2j
z2 = 3 + 4j
# 复数加法
addition = z1 + z2 # (1 + 2j) + (3 + 4j) = 4 + 6j
# 复数乘法
multiplication = z1 * z2 # (1 + 2j) * (3 + 4j) = -5 + 10j
# 访问复数的实部和虚部
real_part = z1.real # 实部为 1.0,实部和虚部都是浮点数
imag_part = z1.imag # 虚部为 2.0,实部和虚部都是浮点数
print(addition)
print(multiplication)
print(real_part)
print(imag_part)文件内容的读取:read()、readline()、readlines()
read()
- read() 方法用于读取整个文件的内容,并将其作为一个字符串返回。
- 如果不指定参数,它会读取整个文件,包括换行符。
- 如果指定了参数 size,它将读取指定数量的字符。
- 当文件被读取完毕后,再次调用 read() 会返回空字符串。
with open("example.txt", "r") as file:
content = file.read() # 读取整个文件内容
print(content)readline()
- readline() 方法用于从文件中读取一行内容,并将其作为字符串返回。
- 每次调用 readline() 会读取文件中的下一行。
- 当到达文件末尾时,再次调用 readline() 会返回空字符串。
with open("example.txt", "r") as file:
line1 = file.readline() # 读取第一行
line2 = file.readline() # 读取第二行
print(line1)
print(line2)readlines()
- readlines() 方法用于读取整个文件的内容,并将其按行分割成一个列表,每行作为列表的一个元素。
- 这个方法通常用于读取整个文件的多行内容。
- 当文件被读取完毕后,再次调用 readlines() 会返回一个空列表。
with open("example.txt", "r") as file:
lines = file.readlines() # 读取整个文件内容,每行作为列表的一个元素
for line in lines:
print(line)isinstance():对象是否是指定类(或类的子类)的实例
isinstance(object, classinfo)其中:
- object 是要检查的对象。
- classinfo 是类(或类的元组)。
isinstance() 函数返回一个布尔值,如果 object 是 classinfo 类(或类的子类)的实例,则返回 True,否则返回 False。
# 定义一个类
class Animal:
pass
# 创建一个对象
dog = Animal()
# 使用 isinstance() 检查对象的类型
result = isinstance(dog, Animal)
print(result) # 输出: True
# 使用 isinstance() 检查对象的类型,也可以检查多个类
result = isinstance(dog, (Animal, str))
print(result) # 输出: True
# 创建一个字符串对象
text = "Hello, world!"
# 使用 isinstance() 检查字符串对象的类型
result = isinstance(text, str)
print(result) # 输出: True
# 使用 isinstance() 检查字符串对象的类型,也可以检查多个类
result = isinstance(text, (str, int))
print(result) # 输出: True
# 使用 isinstance() 检查对象的类型,如果不匹配则返回 False
result = isinstance(dog, str)
print(result) # 输出: Falseissubclass():检查类之间的继承关系
- issubclass(class, classinfo) 用于检查一个类是否是另一个类的子类(派生类)。
- 第一个参数 class 是要检查的类,第二个参数 classinfo 是要比较的类或类的元组。
- 如果 class 是 classinfo 的子类,则函数返回 True,否则返回 False。
class Parent:
pass
class Child(Parent):
pass
result = issubclass(Child, Parent)
print(result) # 输出: True,Child 是 Parent 的子类单下划线_foo、双下划线__foo与__foo__的成员
- 单下划线
_foo
- 以单下划线开头的成员(方法或变量)是被视为“内部使用”或“私有”的惯例,但在 Python 中并没有严格的访问控制机制。
- 单下划线作为前缀的成员可以被访问,但通常被视为不应该直接访问的内部成员。这只是一种约定,没有强制性。
- 双下划线
__foo:
- 以双下划线开头但没有以双下划线结尾的成员,例如
__foo,被用于名称修饰(name mangling)机制,以防止命名冲突。 - Python 会在名称前面添加
_classname,其中classname是包含双下划线的类的名称。例如,在 MyClass 类中,__foo会变成_MyClass__foo。 - 这种机制的目的是确保子类不会意外地覆盖父类的属性或方法,但它并不提供真正的私有性,因为这些成员仍然可以通过修改名称来访问。
- 双下划线前后都有两个下划线
__foo__:
- 以双下划线开头和结尾的成员,例如
__foo__,通常是特殊成员,具有特殊的用途,例如 Python 类中的魔术方法(magic methods)。 - 这些特殊方法用于实现类的某些特定行为,例如构造函数
__init__、字符串表示__str__、等等。 - 用户可以自定义这些特殊方法以控制类的行为,但通常不建议创建自定义的双下划线前后都有两个下划线的成员。
总之,单下划线 _foo 通常用作内部约定,双下划线__foo用于名称修饰以防止命名冲突,双下划线前后都有两个下划线__foo__通常用于特殊成员和魔术方法。但请注意,这些是 Python 中的一些约定和机制,并不是强制性的规则。
continue,break,flag,yield
continue
- continue 是一个控制流程关键字,用于在循环内部跳过当前迭代并继续下一次迭代。
- 当 continue 被执行时,循环内的剩余代码将被跳过,直接进入下一次循环迭代。
continue 常用于循环结构中,用于跳过某些条件下的迭代步骤。
for i in range(5):
if i == 2:
continue # 当 i 等于 2 时跳过当前迭代
print(i) # 输出: 0 1 3 4break
- break 是一个控制流程关键字,用于在循环内部提前结束循环。
- 当 break 被执行时,循环将立即终止,不再执行后续的迭代。
break 常用于循环结构中,用于满足某个条件时提前退出循环。
for i in range(5):
if i == 3:
break # 当 i 等于 3 时提前结束循环
print(i) # 输出: 0 1 2flag
- flag 并不是 Python 中的关键字,而是一个常见的编程约定,通常用于标志(flag)变量的命名。
- flag 变量通常用于控制程序的流程,根据条件的真假来做出不同的决策。
flag = True
while flag:
user_input = input("Enter 'q' to quit: ")
if user_input == 'q':
flag = False
print(flat) # Falseyield
- yield 是一个关键字,用于定义生成器(generator)函数。
- 生成器函数可以生成一系列值,每次调用 yield 时,函数会暂停执行,并返回一个值,然后可以继续执行,直到下次调用 yield。
- yield 用于创建迭代器,它可以节省内存,用于生成大型数据流,而不需要一次性将所有数据存储在内存中。
def generate_numbers():
for i in range(5):
yield i
numbers = generate_numbers()
print(numbers) # <generator object generate_numbers at 0x7f143ee60580>
for num in numbers:
print(num) # 输出: 0 1 2 3 4
not、and、or
优先级not>and>or,谐音not at all
not运算符
- not 运算符用于对一个布尔值进行取反操作,将 True 变为 False,将 False 变为 True。
- 用于表示否定条件。
x = True
y = False
result1 = not x # 结果为 False,因为 x 是 True 的取反
result2 = not y # 结果为 True,因为 y 是 False 的取反and运算符
- and 运算符用于对两个表达式或变量进行逻辑与操作,只有在两者都为 True 时,结果才为 True,否则结果为 False。
- 用于表示两个条件必须同时满足。
x = True
y = False
result1 = x and y # 结果为 False,因为 x 为 True 但 y 为 False
result2 = x and x # 结果为 True,因为 x 为 True 且 x 也为 Trueor运算符
- or 运算符用于对两个表达式或变量进行逻辑或操作,只要其中一个为 True,结果就为 True,只有在两者都为 False 时,结果才为 False。
- 用于表示至少一个条件满足。
x = True
y = False
result1 = x or y # 结果为 True,因为 x 为 True
result2 = y or y # 结果为 False,因为 y 为 False 且 y 也为 False字典的.get()用法
在 Python 中,字典(Dictionary)的 get() 方法用于获取指定键对应的值,如果键不存在于字典中,则可以提供一个默认值来返回,而不会引发 KeyError 异常。get() 方法的语法如下:
dict.get(key, default)其中:
- key 是要查找的键。
- default 是可选参数,如果指定的键 key 在字典中不存在,get() 方法将返回这个默认值,否则返回键 key 对应的值。如果不提供 default 参数,默认值为 None。
Example:
# 创建一个字典
fruits = {"apple": 2, "banana": 3, "cherry": 1}
# 使用 get() 方法获取键对应的值
apple_count = fruits.get("apple")
print(apple_count) # 输出: 2
# 获取不存在的键,提供默认值
orange_count = fruits.get("orange", 0)
print(orange_count) # 输出: 0,"orange" 不存在于字典中,返回默认值 0
# 不提供默认值,返回 None
grape_count = fruits.get("grape")
print(grape_count) # 输出: None,"grape" 不存在于字典中,默认返回 None搜索模块的顺序
python搜索模块的顺序为:内建模块>当前路径,即执行Python脚本文件所在的路径>环境变量中的PYTHONPATH>python安装路径
- 当你导入一个模块时,Python首先会在内置模块(built-in modules)中搜索,这些模块包含了一些核心功能,例如sys和os。
- 如果模块不在内置模块中,Python会搜索已安装的第三方库。你可以使用pip或其他包管理工具来安装这些库。Python会按照系统路径中的顺序查找已安装的库,通常从标准库路径开始。
- 如果模块既不是内置模块也不是第三方库,Python会在当前工作目录中搜索是否存在这个模块的.py文件。如果存在同名的.py文件,Python会将它作为模块导入。
- 最后,如果上述步骤都没有找到所需的模块,Python会引发ModuleNotFoundError异常,指示找不到该模块。
python变量的查找顺序
Python变量作用域查找遵循LEGB原则:
变量的查找顺序:Local 局部作用域->Enclosing 外部嵌套作用域->Global 全局作用域->Built-in 内置模块作用域
- L:Local,局部作用域,也就是我们在函数中定义的变量;
- E:Enclosing,嵌套的父级函数的局部作用域,即包含此函数的上级函数的局部作用域,但不是全局的;
- G:Globa,全局变量,就是模块级别定义的变量;
- B:Built-in,系统内置模块里面的变量,比如int, bytearray等。
.join():字符串列表或元组的拼接
join()函数是Python中用于将字符串序列连接成一个单一字符串的方法。它通常与字符串列表或元组一起使用,并在列表或元组中的每个字符串之间插入一个指定的分隔符,然后返回合并后的字符串。join()函数的语法如下:
separator.join(iterable)- separator:要插入在字符串之间的分隔符。它可以是空字符串 "",或者任何您想要的字符串,例如空格、逗号等。
- iterable:要连接的可迭代对象,通常是包含字符串的列表或元组。
Examples:
# 使用逗号作为分隔符将列表中的元素连接成一个字符串
my_list = ["apple", "banana", "cherry"]
result = ", ".join(my_list)
print(result)
# 输出: "apple, banana, cherry"
# 使用空格作为分隔符将元组中的元素连接成一个字符串
my_tuple = ("red", "green", "blue")
result = " ".join(my_tuple)
print(result)
# 输出: "red green blue"join()函数非常有用,特别是在将多个字符串组合成一个大字符串时。
.split():分割
.split()方法是 Python 字符串(str 类型)的一个内置方法,用于将一个字符串分割成多个子字符串,并将这些子字符串存储在一个列表中。你可以将一个可选的分隔符作为参数传递给 .split() 方法,该分隔符用于指定在哪里分割字符串。如果不传递分隔符参数,它默认使用空格作为分隔符。
string.split([separator[, maxsplit]])- separator(可选参数):指定用于分割字符串的分隔符。如果不提供分隔符,默认使用空格作为分隔符。分隔符可以是字符串或字符。如果分隔符是一个空字符串 '',则字符串中的每个字符都被分割成一个单独的子字符串。
- maxsplit(可选参数):指定分割的最大次数。如果指定了 maxsplit,则字符串将在第 maxsplit 个分隔符处停止分割。剩余的部分将作为单独的字符串元素包含在结果列表中。如果不提供 maxsplit 或将其设置为 -1,则将尽可能多地分割字符串。
.split() 方法返回一个包含分割后子字符串的列表。下面是一些示例:
示例 1:使用默认空格分隔符分割字符串:
text = "I like Python programming"
result = text.split() # 使用默认空格分隔符
print(result) # ['I', 'like', 'Python', 'programming']示例 2:使用自定义分隔符分割字符串:
text = "apple,banana,orange" result = text.split(",") # 使用逗号作为分隔符 print(result) # ['apple', 'banana', 'orange']首位出现空格:这将导致字符串被按照空格进行分割,并将空格字符作为分隔符去除。因此,如果字符串 text 首位有空格,它们将被忽略,并且只分割非空格部分。
text = " I like Python programming " result = text.split(' ') print(result) # ['', 'I', 'like', 'Python', 'programming', '']
示例 3:限制分割次数:
text = "apple,banana,orange,grape"
result = text.split(",", 2) # 限制分割次数为2
print(result) # ['apple', 'banana', 'orange,grape']总之,.split() 方法是在字符串操作中非常有用的工具,它允许你将一个字符串分割成多个子字符串,以便进一步处理或分析。
divmod():执行除法和取余运算,同时返回两个结果
divmod()方法是Python的内置函数之一,用于执行除法和取余运算,同时返回两个结果:商和余数。divmod() 方法接受两个参数,分别是被除数和除数,然后返回一个包含商和余数的元组。
divmod(a, b)其中:
- a 是被除数,可以是任何支持整数或浮点数的类型。
- b 是除数,可以是任何支持整数或浮点数的类型。
divmod() 方法返回一个包含两个元素的元组 (quotient, remainder),其中 quotient 表示除法的商,remainder 表示除法的余数。
Example:
# 整数除法
result = divmod(10, 3)
print(result) # 输出:(3, 1)
# 浮点数除法
result = divmod(10.5, 3.2)
print(result) # 输出:(3.0, 0.8999999999999995)
# 混合类型的除法
result = divmod(10, 3.0)
print(result) # 输出:(3.0, 1.0).endswith():检查字符串是否以指定的后缀(字符串)结尾
.endswith() 是Python字符串方法之一,用于检查字符串是否以指定的后缀(字符串)结尾。该方法返回一个布尔值,如果字符串以指定的后缀结尾,则返回 True,否则返回 False。
str.endswith(suffix, start, end)- suffix:必需参数,表示要检查的后缀字符串。
- start:可选参数,表示开始检查的起始位置,默认为字符串的开头(索引0)。
- end:可选参数,表示结束检查的位置,默认为字符串的末尾(索引 -1)。
Examples:
text = "Hello, World!"
# 检查字符串是否以指定后缀结尾
result1 = text.endswith("World!") # True
result2 = text.endswith("World") # False
result3 = text.endswith("World!", 0, 6) # False
print(result1)
print(result2)
print(result3).update():将一个字典的内容更新到另一个字典中,或者将一个可迭代对象的内容更新到字典中
dictionary.update([other])- dictionary:要更新的字典。
- other:可以是另一个字典或一个可迭代对象,包含了要添加到 dictionary 中的键值对。
Example:
# 定义两个字典
dict1 = {'a': 1, 'b': 2}
dict2 = {'b': 3, 'c': 4}
# 使用 update() 方法将 dict2 中的内容更新到 dict1 中
dict1.update(dict2)
print(dict1) # 输出: {'a': 1, 'b': 3, 'c': 4}在上面的示例中,dict1 和 dict2 是两个字典。通过调用 dict1.update(dict2),dict1 中的内容被更新,将 dict2 中的键值对合并到 dict1 中。如果存在相同的键(如 "b"),则更新其对应的值。
此外,如果 other 是一个可迭代对象,它应该包含键值对元组,如下所示:
# 使用可迭代对象更新字典
dict1 = {'a': 1, 'b': 2}
iterable = [('b', 3), ('c', 4)]
dict1.update(iterable)
print(dict1) # 输出: {'a': 1, 'b': 3, 'c': 4}.update() 方法是一种很有用的方法,用于合并字典或将多个键值对添加到字典中,以便在处理数据时能够动态更新字典的内容。
.center():将字符串居中对齐,并在两侧填充指定的字符
.center() 方法是 Python 字符串的一个方法,用于将字符串居中对齐,并在两侧填充指定的字符(默认为空格)以达到指定的总宽度。这个方法可以用于美化输出格式或格式化字符串。
str.center(width, fillchar)- width:指定字符串的总宽度,包括原始字符串的长度和填充字符的数量。
- fillchar(可选):要用于填充的字符,默认为空格。
text = "Python"
centered_text = text.center(10,'*')
print(centered_text) # 输出: "**Python**"修饰器(非内置修饰器)
装饰器是 Python 中一种强大的编程概念,用于修改或增强函数或方法的行为,而无需修改它们的源代码。装饰器允许你在不改变原始函数的情况下,通过包装(或装饰)它们来添加额外的功能或修改其行为。装饰器通常用于日志记录、性能分析、权限检查、输入验证等方面。
装饰器的一个关键特性是,它们在被装饰的函数定义之后立即运行。
下面详细解释一下装饰器的工作原理和如何创建自定义装饰器:
- 函数作为参数:装饰器是函数,它接受另一个函数作为参数。被装饰的函数通常称为目标函数。
- 内部函数:装饰器内部通常定义一个内部函数,用于包装目标函数。这个内部函数可以访问并修改目标函数的行为。
- 返回函数:装饰器内部函数通常返回一个新的函数,这个新函数通常会调用原始的目标函数,并在必要时添加额外的功能。
- 装饰过程:在使用装饰器时,你将目标函数用@符号放在装饰器函数的上面,告诉 Python 使用装饰器来包装目标函数。
Examples1:
# 定义一个装饰器函数
def my_decorator(func):
def wrapper():
print("Something is happening before the function is called.")
func()
print("Something is happening after the function is called.")
return wrapper
# 使用装饰器
@my_decorator
def say_hello():
print("Hello!")
# 调用被装饰的函数
say_hello()输出为:
Something is happening before the function is called.
Hello!
Something is happening after the function is called.在这个示例中,my_decorator 是一个装饰器函数,它接受一个函数 func 作为参数,然后定义了一个内部函数 wrapper,该函数在目标函数 func 前后执行一些操作。最后,my_decorator 返回 wrapper 函数。
当你用 @my_decorator 装饰 say_hello 函数时,当你调用 say_hello() 时,实际上是调用了 wrapper() 函数,因此在执行 say_hello() 之前和之后,会打印出额外的消息。
Example2:
def dec(f):
n = 3
def wrapper(*args,**kw):
return f(*args,**kw) * n
return wrapper
@dec
def foo(n):
return n * 2
foo(2) # foo(2) = 3 * foo(2) = 3 * (2 * 2) = 12
foo(3) # foo(3) = 3 * foo(3) = 3 * (3 * 2) = 18总结:装饰器是一种强大的工具,允许你在不修改原始函数代码的情况下,动态地添加、修改或扩展函数的行为。这种方式有助于保持代码的可维护性和可重用性,并允许你将功能分解为多个独立的组件。
.copy();copy.copy();.deepcopy():浅拷贝和深拷贝
在Python中,拷贝操作是将一个对象的内容复制到另一个对象中。Python中的拷贝操作通常涉及到可变对象(列表、字典、集合等)和不可变对象(整型、浮点数、元组、字符串等)的复制,以及深拷贝和浅拷贝两种不同的方式。
对于不可变类型而言,赋值、浅拷贝和深拷贝无意义,因为其永远指向同一个内存地址。
- 对于不可变对象,浅拷贝和深拷贝都是相同的。
- 对于可变对象,浅拷贝只会复制对象的一层内容,不会递归复制对象的子对象。如果需要递归复制子对象,必须使用深拷贝。
- 对于包含循环引用的对象,深拷贝可能会陷入无限递归,导致程序崩溃。因此,在使用深拷贝时,必须小心处理包含循环引用的对象。
- 在使用深拷贝时,如果对象的层次结构比较复杂,可能会导致性能问题,因此必须小心使用深拷贝。
- 浅拷贝(Shallow Copy):
浅拷贝创建了一个新的对象,但是只复制了原始对象中的引用,而不是复制引用指向的对象本身。这意味着,如果原始对象中包含了==可变对象==(如列表或字典),那么浅拷贝后的对象仍然会引用相同的可变对象,从而可能会导致原始对象和拷贝对象之间的修改相互影响。浅拷贝只复制对象的一层内容。
浅拷贝可以使用以下方式进行:
.copy()copy.copy()
- 深拷贝(Deep Copy)
深拷贝是指创建一个新的对象,然后递归地复制原始对象及其子对象的所有内容。新对象与原始对象完全独立,不共享内存地址,因此改变其中一个对象的值不会影响另一个对象的值。
import copy
copy.deepcopy()图解:
import copy
a = [1,2,3,[4,5,6,[7,8,9]]]
b = a.copy()
a[0] = 0
a[3][0] = 1
c = copy.deepcopy(a)
c[3][0] = 100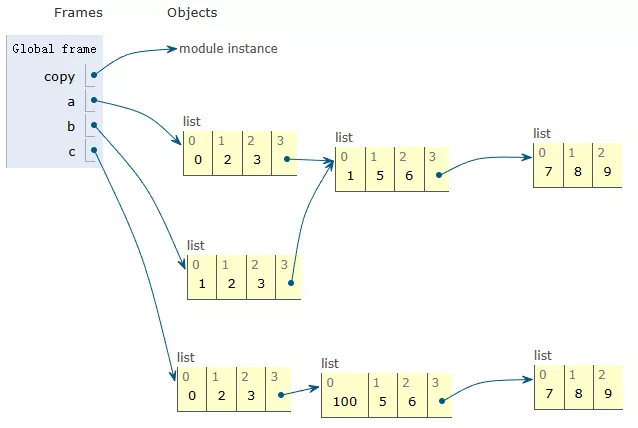
从图中可以看出,使用.copy()浅复制时,只复制了列表的第一层,之后的层直接引用。修改a的第一层中的元素进行修改并不会影响到b的第一层。修改a的第二层或第三层,b也会同步修改。而深拷贝则是全新的列表,无论怎么修改都不会相互影响。set():集合
在Python中,集合(Set)是一种无序(不能索引)且==不重复==的数据结构,用于存储一组唯一的元素。Python中的集合通常用于执行集合操作,例如交集、并集和差集等。集合是可变的,这意味着你可以添加、删除和修改集合中的元素。
- 创建集合
创建集合:
你可以使用大括号 {} 或 set() 构造函数来创建一个集合。注意,如果使用大括号创建空集合,将创建一个字典,而不是一个集合。因此,要创建空集合,你应该使用 set() 构造函数。示例:
my_set = {1, 2, 3} # 集合
empty_set = set() # 空集合- 添加元素
你可以使用 add() 方法来向集合中添加元素。
my_set.add(4)- 删除元素
你可以使用 remove() 或 discard() 方法来删除集合中的元素。区别在于,remove() 方法会引发 KeyError 如果要删除的元素不存在,而 discard() 方法则不会引发异常。示例:
my_set.remove(2)
my_set.discard(5)- 集合操作
Python提供了一系列用于执行集合操作的方法,例如并集、交集、差集等。这些操作可以用于比较和组合不同集合。
set1 = {1, 2, 3}
set2 = {3, 4, 5}
union_set = set1 | set2 # 并集 {1, 2, 3, 4, 5}
intersection_set = set1 & set2 # 交集 {3}
difference_set = set1 - set2 # 差集(set1 中存在但在 set2 中不存在的元素) {1, 2}- 遍历集合
你可以使用循环来遍历集合中的元素。集合是无序的,所以不能通过索引访问元素,但可以使用 for 循环来迭代元素。
for item in my_set:
print(item)- 集合方法
Python提供了许多集合方法,如 clear()(清空集合)、copy()(复制集合)、len()(获取集合大小)等。
size = len(my_set)